How to write a modern webservice part 1
Welcome to this series on how to write a modern web service.
What do I mean by this: (Caution, buzzwords ahead, get your Bingo sheet ready)
- almost linear scalable across multiple cores and machines (twice the CPU count, twice the throughput)
- resource friendly, low CPU,RAM usage
- based upon multiple tiers of micro services
- based on async IO
I will be building this in C++, but most of the logic should work in other programming languages. Scaling across multiple CPU cores might not be possible in all languages.
The big picture
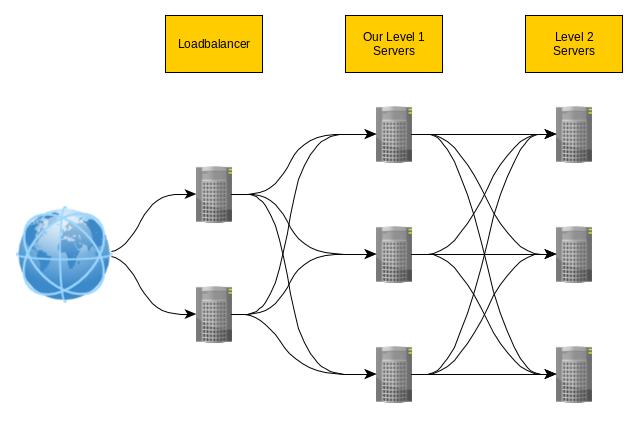
This is the general architecture:

I will only describe the logic or our level 1 servers. All layers could be done in a similar way. Just the input/output is different.
As load balancers I will use an existing haproxy setup, the level 2 servers are just blackboxes that response to requests. These can be local or remote (somewhere in the internet).
As a basic thing, there should always be at least 2 instances on each level just in case of a software or hardware failure or just planned downtime due to upgrades a.s.o.
In my case, this will be http(s) requests coming from the internet with json payload (this will be an API). Haproxy deals with the encryption stuff and sends the data via http on to one of my application servers. Each of them listen for the http requests, process them, queries some internal data, does some heavy CPU lifting and creates a new request to next level of services. In my case, this is an external service provider speaking https. I will put another haproxy instance in front the external service, which does the http => https thing, so I only need to speak and understand http on both sides. When the response comes back (could be tens to hundreds of milliseconds) the response is processed again and send on to the original requester.
General design rules
So to pick up the buzzword from the beginning, what do each of those mean in practical design decisions?
To explain a basic issue, have a look at the c10k problem a few decades ago. Basically it describes the issues and solutions on how to handle 10.000 simultaneous connections in a server application.
It is not as trivial as a naive programmer might think.
I will use a hybrid approach of two solutions. One part is using asynchronous or non-blocking IO. The other part is using multiple threads.
Async IO and multithreading
Let's dive into network programming a bit. On "normal" blocking IO you have your already open socket and read from it. The call to read() will block until a given amount of data has come in. Details vary by function and programming language, but all of them block. So your program does nothing. So you need a thread or process for every connection that each waits until something happens. This blocks resources (Threads/Processes come with a cost) and loads the IO stuff onto the Task Scheduler of the operating system, which is not designed for. Also the os probably won't like having 10.000 threads open.
Now here comes the async to rescue. If you set the connection into async mode, the above read will return right now, either with some data that was already waiting or with "no data there" response. So if the thread got this no data response, it can bother another socket and check there until it starts over or one of the connections had work to do. If there was work, process it and resume checking the connections. This is called polling. Now change this to not only 1 thread going through the socket, but multiple ones. That way you can handle multiple incoming requests at the same time.
But this polling is basically a bad idea, because it wastes CPU time (see design goal).
The kernel developers (Linux, *BSD and MicroSoft) created various solutions for this issue. Basically all of them have in common that you register a list of sockets or file handles that you want to monitor, call a function and this blocks until at least one of the monitored elements has data to read from. The returned data tells which one. As far as I know, you can have multiple threads waiting on the same socket list. Maybe two get waken up, so make sure you have some protection in place.
So in summary, you create a pool of threads, a pool of opened connections and let the 10.000 connections get handled by a number of Threads (optimally the number of CPU cores you have). Minimal resource overhead, only a handful of threads (unless you run on crazy hardware) and just the normal socket overhead that you need anyway and this little monitoring structure.
What about the issue that I send data along to an external service and the response comes back a long time later (from a computer's perspective)?
Basically we do the same, when we sent the data out, put the connection back in the waiting pool. If the response comes back, it gets picked up and the processing goes on.
Data storage
The service needs to have some config options, database things and similar to do the processing. Here a similar approach can be used, if you have to deal with "external" data. But in my case, the amount of data is minimal, I just load it into internal data structures during startup or when I receive an reload event. That way a broken or slow database won't affect the service until it is restarted. This won't work with terabytes of data, but here there are only a handful of MB. Also this ensures linear scalability, add an extra machine and it will handle linear more requests.
Keep track of status
As mentioned above, we have incoming requests and backend (outgoing) requests managed by the same connection pool. To make live easier, we store all relevant request data with that socket. Luckily there are ways to do that, otherwise you can always create a helper structure like a unordered_map, hashmap, dictionary or however your programming language calls it. Key is the socket/file handle, value is the storage class instance.
Since this is a paid programming job for a company I can't release the source of it. But given the rough description above you should get some good pointers on how to build something for your need.
I'll post updates if interesting things worthy of explaining happen.